This is the last week for blogs that will be marked for my PRJ701 class. This whole experience has been amazing and i have learnt a lot of things i wouldn’t of expected or gotten from courses at NMIT or online. So what have i been doing this week?
I did another failed test with darkflow, so my comparison between machine learning or computer vision is pretty clear which one is better for this problem. However, I have been needing darkflow to work for auto cropping the images, so im gonna need a way to crop with computer vision.
After a good days research on potential opencv methods that could work, I settled on using an erosion process, which scans the images with a kernel and gets the average color. From here, I am able to remove areas that don’t match the fishes color range and thus, leaves me with an area where i can auto crop.
So whats next? well my software is all done and pushed to a repo. My report is done, i just need to go through and proof read it a couple more times. My poster is coming along nicely and just needs some data numbers to show results of my software. Lastly, its time to be looking for a job before the whole last year crew is competing against each other for a job. oh and finish DAT701
This week was another big research week for me! This past week I was polishing up my code with more comments, documentation and an easy to navigate Git Repository. I also had a good talk with my supervisor about how to modify the machine learning aspect to get better results and we came to the conclusion to test out Yolov2 instead of tiny yolo, which was a light weight solution, where as yolov2 is a heavy but better version.
I was also polishing up my report and getting the PFR poster sorted as these need to be handed in sooner than the other students to go through PFR first.
Other than that, I also attended my first start up weekend and we ended up getting second! but also gained a lot of attention from potential investors which was really fun! I was under to get a better understanding about business models, financial models and better knowledge of data analytics. Over 52 hours, we were able to complete all these things, talk to all sorts of people like the mayor of multiple cities, survey over 100 people and more! It was a crazy but worth wild event.
This past week has been a very productive one. For the first half of it I was back into my code to refactor and simplify the process for the user. I was able to drop the code by half and completely remove the user needing to input values to change the filters. I decided to do that as this software will only be used for a couple months each year and the user will forget what all the special numbers mean. Also with the simplified code, I decided to give another crack at OpenCV js and it works surprisingly well and has the added effect of not needing to be run locally, so hopefully this could be another option.
The other part of the week was researching at ITx Rutherford 2019, which if you wish to hear about that, the next three posts below is about my experience.
The last day luckily started at 10 to give up a couple more hours of sleep after the dinner drinks. The day started a couple presentations that i honestly couldn’t remember, i think i needed a coffee
DGGS – new format for spatial data
By far the best presentation for the day that i seen was by Byron Cochrane and his talk about Discreet Global Grid Systems. This format solves the issue of how to properly convert the earth or spheres to a flat / 2D object without causing any errors or stretching. In simple terms, its a way of better identifying a location than Long and Latitudes as it creates arrays inside arrays. Its hard to explain but the image i created below can give a simple level understanding. The boxes can go on infinitely to give a better accuracy on the location needed.
Digital Marketing
Another great presentation was by Doyun Kim who has worked at LG, Samsung and many other big name companies. His talk was about how digital marketing has taken over the traditional form and is a lot more about UX. He discussed three forms of marketing
Owned Media – website, app and other things created by the company themselves.
Brought Media – sponsored ad placements in Facebook, TV, YouTube, google, etc
Earned Media – Satisfied customers sharing their experience and word of mouth is a form of free marketing
The Story of Seeby Woodhouse
The last one for the conference was the story about Seeby Woodhouse who built up Orcon and how all the money didn’t bring him happiness.
Day two is the official start of ITP presentations and is the main day of the conference as the amount of people who turned up was huge! This day was very busy and luckily I wasn’t one of the volunteer students because they had heaps to do!
Trends and Ethics of AI
First up was a key note by the AI guru himself, Dheeren Velu who does talks all around the world and a couple TEDx talks. His talk was very high level, but was still very informative. He talked about how we need to disconnect the connection between A.I. and things like Skynet(terminator) and should embrace AI. After that he talked about the new AI by IBM called “Project Debater”, which has over 10 billion sentences and goes up against the worlds best debater. In the end the human debater won because he could connect with the audience, but the machine was able to back themselves up with true facts. It was truly amazing to watch and I’ve linked it for you to watch if you wish.
After that he went on to talk about the ethics around GANS or commonly known as DeepFakes and how far they have come and the possible issues that arise with deep fakes. The video shows Deep fakes off by turning Bill Hader into Tom Cruise seamlessly (and Seth Rogen if you spot it)
Christchurch Call
I remember very vividly when the Muslim attack in Christchurch happened. I was in Research Class when my facebook and all social media was flooded with people sharing that video and as an IT person, I personally felt helpless as it was going on, so going to this presentation by Jordan Carter of Internet NZ, I really was interested in what NZ and the rest of the world is doing to fix the social media terrorism. The talk was more of an update on what the world is doing to combat this issue and what new protocols have been created. One down side is they are facing is A.I. isn’t able to tell the difference between video games and real attacks.
Law and Data
Who really owns the data? was a great talk by Andrew Dentice. He went through the three big point of views that lawyers use in cases involving data.
Legislation – This data is of ME, so it should be mine
Intellectual Property – The data wouldn’t exist without my company making the app and translating the information into data, so it should be the companies. This view is useful against other companies who are trying to copy, but doesn’t out rule legislation
Contracts – Those “terms and conditions” that everyone totally reads. These are put in place to fill in any “void” areas.
I really enjoyed this talk as someone who wanted to be a lawyer originally.
Carbanak Gang
There was so many amazing things I attended on day two, so ill try keep it short, but i have to mention the Carbanak gang, who stole 1 Billion dollars. In short, they created a security company of white hat hackers who thought they were “testing” companies, but in reality was stealing millions of dollars from banks and only the higher ups knew about it.
Dinner
The dinner at a 5 star hotel was pretty surreal and being able to network with all sorts of IT professionals in a less professional setting was by far the best part of the whole event and was defiantly worth it!
First day at IT conference starts with a day of presentations and papers by CITRENZ(Computing and Information Technology Research and Education New Zealand). After the warm welcome by the ITP community and staff, we got to hear our first presentation by Clarke Ching.
Clarke Ching is the author of “Rolling Rocks downhill” and “The Bottleneck Rules” and he talked about how usefull agile is and the act of “going slower” is better for the company. A great saying he said was “we can only go as the slowest department” and in most cases that is the testing/bug fixing teams.
Through out the day i went to nine talks so I will just highlight some my favorites for day one.
Morepork Vocalization
Presented by Tim Hunt, this was properly one of the most impressionable talks over the three days. His talk was about The Cacophony Project, where he built a mobile app that records wild life noises, in the hopes of capturing enough data to figure out if the birds are in danger of prey, how many there are, etc. I really liked this talked because of how they are reusing old phones to capture data and training with 100% open source content. I will definitely research more into this project and hopefully participate in helping them.
Naive approaches to AI
Riley Hunter talked about how there has been a big trend around “AI” and this has lead to a rise in people jumping onto the trend without correctly understanding the approaches and more importantly extracting the correct data from their sets. The example he used was about an AI that would pick the list the best students for the class, however the maker added gender, race and country origin data into the system which created an ethically wrong AI that shouldn’t have that information as a deciding factor.
Computer Vision on FPGA
The last notable presentation was by Firas Al-Ali. He talked about a new FPGA( Field Programmable Gate Arrays ) chip. Usually computer vision and machine learning focuses on using the process of CPU and recently GPU but with this new chip called PYNQ, which was a chip that he programmed to run machine learning predictions and the results was 500 times faster than GPU! This one was really interesting as we are still furthering the technology of how machine learning is working and I will defiantly be looking into buying one to mess around with in the future.
This week i have been discussing with the PFR supervisor in how I should export the data captured from my python software. At the time of writting, the desired format is CSV.
CSV stands for Comma Separated Values and it is a very streamlined and simple form of data storage when compared to my preference of SQL. CSV is being used because the environment of PFR uses excel and excel has a built in csv converter, which fills the CSV into cells. Below is the format of CSV.
The first row is declaring the columns, then each line is a row of data.
Python Intergration
So how do we add CSV into a python program? Im using Python 3.7, however i believe the context hasn’t changed much from previous editions.
import csv
# filelocation is the directory and file you wish to update/create
#newdata is the information you wish to input
try:
with open(filelocation,'r',newline='') as readFile:
reader = csv.reader(readFile)
#Get all existing data
lines = list(reader)
for r in lines:
#if the image column already has the image name, update row instead of adding
if r[0] == ImageName:
index = lines.index(r)
lines[index] = newdata
if newdata not in lines:
lines.append(newdata)
#insert all the new data
with open(filelocation,'w',newlines='') as writeFile:
writer = csv.writer(writeFile)
writer.writerows(lines)
#if the above fails, it means the file does not exist, so create a new one
except Exception as e:
print(e)
with open(filelocation,'w',newline='') as newFile:
writer = csv.writer(newFile)
writer = writerows([['Image,column2'],newdata])
With my new found power of CVAT, I am able to label without any hardware issues and its amazing! So now I have two different datasets im gonna train. The first one is labeling all the fish, which is a big project and the other one is to label and identify just where the fish is.
My PFR supervisor and I decided to make a box identifier to be built onto the OpenCV system to auto crop the images for the employees and simplify the process, so after annotating all the images, it was time to send it off to be trained!
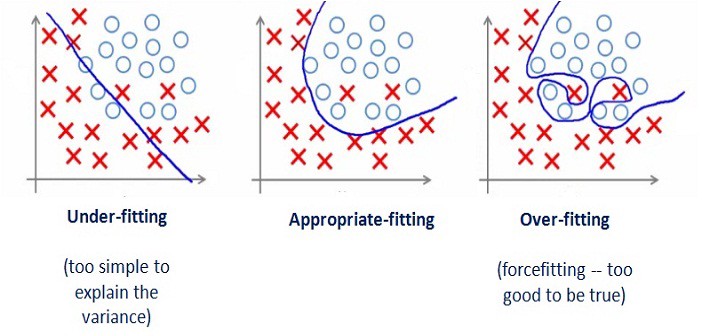
A couple days have passed and its the best results i have ever had! It had dropped to 0.01 accuracy, which is amazing, it must work? right?
After running it through my small test environment to see if it can predict where the bin is, i was met with this small line…
As we can see from above, their is nothing inside the list, so it didn’t end up finding anything and predicting, but how? the accuracy is at 0.01?
Overfitting
Over fitting is the terminology that is used in statistics and machine learning. It is where the data formula is too accurate to the data it knows, so when new data is added, it doesn’t know what to do with it because its threshold is so close to the original data. Within machine learning in particular, the machine begins to memorize the data instead of actually learning from it.
How do we fix it?
Well there are many different solutions and some that i will be trying over the week will be increasing the data set size and applying higher drop rates. drop rates is the rate that some data randomly gets deleted so the machine can’t just remember the process and will have to actually learn. A good article by Ashish Patel explains this problem in better detail and worth a read if you are interested.
ITP Events
Last week i mentioned going to a small conference about data visualization and it was my first time going to an ITP event so I wasn’t sure what to expect, however it was extremely interesting to hear about what professionals in our community are building and how data visualization was helping them achieve that.
On the topic of ITP. I recently was given the chance to go attend ITx Rutherford 2019 for free! which i am extremely excited to go to as I have been reading and saving up for it since it was first announced at the start of the year. ITx Rutherford 2019 is a combination of ITP and CITRENZ events over a full three days. This event focuses on innovation, technology, education and bringing hundreds of IT professionals together.
The development is beginning to slow down and I am mainly focusing on the report, poster and building a big dataset for PFR to use in the future.
Plans for this week
Just continue to debug the opencv software, write the report and build the dataset up as im already over 7,000 annotations.
Outside of my project, I will be attending an ITP event in nelson on Wednesday, that’s all about data and visualization which will be fun to listen to! The event is being presented by Krupesh Desai and Tama Easton.
Last time I talked about machine learning, I was having a bit of issues with my system running out of memory so it was not able to correctly train and i was not able to correctly label the images. So since then, employees at Plant and Food Research have set up a web server that hosts a labeling tool, so I am able to label the thousands of fish without running into frame rate and crashing issues.
The new labeling tool we are using is called CVAT, which i personally prefer over VoTT as it supports all annotation formats like TFrecords, Pascal VOC, YOLO and COCO. CVAT also allows for object segmentation which is another level deeper than object detection as it allows the user to make polygon outlines around objects instead of simple bounding boxes. Below is an example from the CVAT github
However as of now and the time i have left, i will stay with using just bounding boxes and darknet as it is all set up and ready to go, it just needs a correct dataset. So its back to drawing around fish for the next couple weeks and as a result, to pass the time, i have been listening to ‘The O’Reilly Data Show’ podcast. It is around 40 minute talks with some of the most popular machine learning specialists from around the world as they explain what they are doing at the moment, current issues and theories around data and machine learning.